显著性差异
統計學的假說檢定中[1][2],顯著性差異(或统计学意义,英語:statistical significance)是對數據差異性的評價,當某次實驗的结果在虛無假說下不大可能发生时,就認為該結果具有顯著性差異。更準確而言,譬如某項研究設定了一個數值α(顯著水準),表示虛無假說本來正確但卻被拒絕的出錯概率[3](並非虛無假設為真的機率、對立假設為假的機率、實驗再現失敗率[4]),然後用p值表示虛無假說条件为真時得到某結果或更極端结果的概率[5]。當p ⩽ α時,就可以認為結果具有統計學意義,或數據之間具有了顯著性差異。[6][7][8][9][10][11][12]顯著水準應當在開始數據收集前就設定,通常習慣設定為5%[13]或更低,因研究的具體學科領域而異。[14]
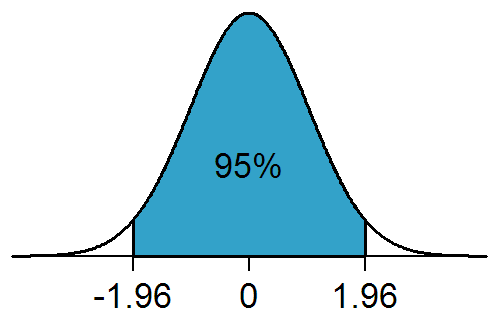
在任何涉及到从总体中抽取样本的实验或观察性研究中,观察到的结果都有可能只不过是由抽样误差产生的。[15][16]但是,如果一个观察结果的p值小于(或等于)显著性水平α,研究者就可以得出“该结果能反映总体的特征”的结论[1],并拒绝零假设[17]。
顯著性差異的原因可能是:
歷史
编辑顯著性差異的提出可追溯到18世纪,约翰·阿巴思诺特和皮埃尔-西蒙·拉普拉斯作出了男女出生概率均等的零假设,然后计算了人类出生时性别比的p值。[18][19][20][21][22][23][24]
1925年,羅納德·費雪在《研究工作者的统计方法》一书中提出了统计假设检验的思想,称之为“显著性检验”(tests of significance)。[25][26][27]費雪建議将1/20(=0.05)的概率作为拒绝虛無假說的一个截断值。[28]在1933年的一篇论文中,耶日·内曼和埃贡·皮尔逊把这个截断值称为“显著性水平”,並賦予它符號α。他们建议,α值應當在收集任何数据收集之前提前设定。[28][29]
費雪最初將显著性水平定為0.05,但他并不打算将这一截断值定死。在他1956年出版的《统计方法与科学推断》一书中,他建议根据具体情况确定显著性水平。[28]
相關概念
编辑显著性水平α是p值的阈值,當p ⩽ α時就拒絕零假设(即使零假设仍有可能是正确的)。这意味着α也是在零假设正确的情况下错误地将其否定的概率[3],称为伪阳性或型一錯誤、棄真錯誤、α錯誤。
而有些研究者偏好使用置信水平γ = 1 − α。它是零假设成立时不拒绝零假设的概率。[30][31]置信水平和置信区间是Neyman于1937年提出的。[32]
顯著水準
编辑顯著水準(significance level,符號:α)常用于假设检验中检验假设和实验结果是否一致,它代表在虛無假說(記作 )為真時,錯誤地拒絕 的機率,即發生型一錯誤(棄真錯誤、α錯誤)的機率。
比如,我們從兩個母體中分別抽取了兩組樣本數據A和B,這兩組數據在顯著水準α = 0.05下具備顯著性差異。這是說,兩組數據所代表的母體具備顯著性差異的可能性為95%;但它們代表的母體仍有5%的可能性是沒有顯著性差異的,這5%是由於抽样误差造成的。也可表述为:
- 如果拒绝“两组数据一致(二者不具备显著性差异)”的零假设(接受“两组数据不一致”的备择假设),此时有5%的可能性犯第一类错误;
- 如果A=两组数据不具备显著差异;B=实际数据具有显著差异,則P(A|B) = 0.05,即統計100次,預期是B情況,但可能出現5次的A情況。
當假說檢定所測得之數據之間具有顯著性差異,實驗的虛無假說就可被推翻,也就是拒絕 ,接受對立假說(alternative hypothesis,記作 或 );反之,若數據之間不具備顯著性差異,則拒絕對立假說,不拒絕虛無假說。通常情況下,實驗結果需要證明達到顯著水準α = 0.05或0.01,才可以說數據之間具備了顯著性差異,否則就如上所述,容易作出錯誤的推論。在作結論時,應確實描述方向性(例如顯著大於或顯著小於)。
数学表述为:引入p值作为检验样本(test statistic)观察值的最低顯著水準。在α = 0.01或α = 0.05的条件下,若零假设成立的概率(p)小于α,则表示零假设成立的情况下得到这种观测结果的概率,比1%或5%還低,在该显著性水平下,我们可拒绝该零假设。
P(X=x)<α=0.05为“显著(significant)”,统计分析软件SPSS中以*标记;P(X=x)<α=0.01为“极显著(extremely significant)”,通常以**标记。
局限性
编辑研究人员常常只关注他们的结果是否具有统计学意义,但其报告的结果可能并没有实质性[33],或者研究结果无法重現[34][35]。统计学意义与实际意义之间也不能等同,有统计学意义的研究未必就有实际意义。[36][37]
效应值
编辑效应值是衡量一项研究的实际意义。[36]统计上显著的结果可能效应量很低。为了衡量结果的研究意义,研究人员最好同时给出效应值和p值。效应量量化了效应的强度,例如以标准差为单位的两个平均值之间的距离(Cohen's d)、两个变量之间的相关系数或其平方,以及其他度量。[38]
再现性
编辑统计上显著的结果未必能够轻易重現。[35]特别是一些有显著性差异的结果实际上是假阳性。重现结果每失败一次,都意味着研究结果实际上为假阳性的可能性增加。[39]
参见
编辑参考文献
编辑- ^ 1.0 1.1 Sirkin, R. Mark. Two-sample t tests. Statistics for the Social Sciences 3rd. Thousand Oaks, CA: SAGE Publications, Inc. 2005: 271–316. ISBN 978-1-412-90546-6.
- ^ Borror, Connie M. Statistical decision making. The Certified Quality Engineer Handbook 3rd. Milwaukee, WI: ASQ Quality Press. 2009: 418–472. ISBN 978-0-873-89745-7.
- ^ 3.0 3.1 Dalgaard, Peter. Power and the computation of sample size. Introductory Statistics with R. Statistics and Computing. New York: Springer. 2008: 155–56. ISBN 978-0-387-79053-4. doi:10.1007/978-0-387-79054-1_9.
- ^ 平克, 史蒂芬. 理性. : 282.
- ^ Statistical Hypothesis Testing. www.dartmouth.edu. [2019-11-11]. (原始内容存档于2020-08-02).
- ^ Johnson, Valen E. Revised standards for statistical evidence. Proceedings of the National Academy of Sciences. October 9, 2013, 110 (48): 19313–19317. Bibcode:2013PNAS..11019313J. PMC 3845140
. PMID 24218581. doi:10.1073/pnas.1313476110
- ^ Redmond, Carol; Colton, Theodore. Clinical significance versus statistical significance. Biostatistics in Clinical Trials. Wiley Reference Series in Biostatistics 3rd. West Sussex, United Kingdom: John Wiley & Sons Ltd. 2001: 35–36. ISBN 978-0-471-82211-0.
- ^ Cumming, Geoff. Understanding The New Statistics: Effect Sizes, Confidence Intervals, and Meta-Analysis. New York, USA: Routledge. 2012: 27–28.
- ^ Krzywinski, Martin; Altman, Naomi. Points of significance: Significance, P values and t-tests. Nature Methods. 30 October 2013, 10 (11): 1041–1042. PMID 24344377. doi:10.1038/nmeth.2698
- ^ Sham, Pak C.; Purcell, Shaun M. Statistical power and significance testing in large-scale genetic studies. Nature Reviews Genetics. 17 April 2014, 15 (5): 335–346. PMID 24739678. S2CID 10961123. doi:10.1038/nrg3706.
- ^ Altman, Douglas G. Practical Statistics for Medical Research
. New York, USA: Chapman & Hall/CRC. 1999: 167. ISBN 978-0412276309.
- ^ Devore, Jay L. Probability and Statistics for Engineering and the Sciences 8th. Boston, MA: Cengage Learning. 2011: 300–344. ISBN 978-0-538-73352-6.
- ^ Craparo, Robert M. Significance level. Salkind, Neil J. (编). Encyclopedia of Measurement and Statistics 3. Thousand Oaks, CA: SAGE Publications: 889–891. 2007. ISBN 978-1-412-91611-0.
- ^ Sproull, Natalie L. Hypothesis testing. Handbook of Research Methods: A Guide for Practitioners and Students in the Social Science 2nd. Lanham, MD: Scarecrow Press, Inc. 2002: 49–64. ISBN 978-0-810-84486-5.
- ^ Babbie, Earl R. The logic of sampling. The Practice of Social Research 13th. Belmont, CA: Cengage Learning. 2013: 185–226. ISBN 978-1-133-04979-1.
- ^ Faherty, Vincent. Probability and statistical significance. Compassionate Statistics: Applied Quantitative Analysis for Social Services (With exercises and instructions in SPSS) 1st. Thousand Oaks, CA: SAGE Publications, Inc. 2008: 127–138. ISBN 978-1-412-93982-9.
- ^ McKillup, Steve. Probability helps you make a decision about your results
- ^ Brian, Éric; Jaisson, Marie. Physico-Theology and Mathematics (1710–1794). The Descent of Human Sex Ratio at Birth. Springer Science & Business Media. 2007: 1–25. ISBN 978-1-4020-6036-6.
- ^ John Arbuthnot. An argument for Divine Providence, taken from the constant regularity observed in the births of both sexes (PDF). Philosophical Transactions of the Royal Society of London. 1710, 27 (325–336): 186–190 [2022-06-19]. doi:10.1098/rstl.1710.0011
- ^ Conover, W.J., Chapter 3.4: The Sign Test, Practical Nonparametric Statistics Third, Wiley: 157–176, 1999, ISBN 978-0-471-16068-7
- ^ Sprent, P., Applied Nonparametric Statistical Methods Second, Chapman & Hall, 1989, ISBN 978-0-412-44980-2
- ^ Stigler, Stephen M. The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press. 1986: 225–226. ISBN 978-0-67440341-3.
- ^ Bellhouse, P., John Arbuthnot, in Statisticians of the Centuries by C.C. Heyde and E. Seneta, Springer: 39–42, 2001, ISBN 978-0-387-95329-8
- ^ Hald, Anders, Chapter 4. Chance or Design: Tests of Significance, A History of Mathematical Statistics from 1750 to 1930, Wiley: 65, 1998
- ^ Cumming, Geoff. From null hypothesis significance to testing effect sizes. Understanding The New Statistics: Effect Sizes, Confidence Intervals, and Meta-Analysis. Multivariate Applications Series. East Sussex, United Kingdom: Routledge. 2011: 21–52. ISBN 978-0-415-87968-2.
- ^ Fisher, Ronald A. Statistical Methods for Research Workers. Edinburgh, UK: Oliver and Boyd. 1925: 43. ISBN 978-0-050-02170-5.
- ^ Poletiek, Fenna H. Formal theories of testing. Hypothesis-testing Behaviour. Essays in Cognitive Psychology 1st. East Sussex, United Kingdom: Psychology Press. 2001: 29–48. ISBN 978-1-841-69159-6.
- ^ 28.0 28.1 28.2 Quinn, Geoffrey R.; Keough, Michael J. Experimental Design and Data Analysis for Biologists 1st. Cambridge, UK: Cambridge University Press. 2002: 46–69. ISBN 978-0-521-00976-8.
- ^ Neyman, J.; Pearson, E.S. The testing of statistical hypotheses in relation to probabilities a priori. Mathematical Proceedings of the Cambridge Philosophical Society. 1933, 29 (4): 492–510. Bibcode:1933PCPS...29..492N. doi:10.1017/S030500410001152X.
- ^ "Conclusions about statistical significance are possible with the help of the confidence interval. If the confidence interval does not include the value of zero effect, it can be assumed that there is a statistically significant result." Prel, Jean-Baptist du; Hommel, Gerhard; Röhrig, Bernd; Blettner, Maria. Confidence Interval or P-Value?. Deutsches Ärzteblatt Online. 2009, 106 (19): 335–9. PMC 2689604
- ^ StatNews #73: Overlapping Confidence Intervals and Statistical Significance (PDF). [2022-06-19]. (原始内容 (PDF)存档于2020-06-21).
- ^ Neyman, J. Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability. Philosophical Transactions of the Royal Society A. 1937, 236 (767): 333–380. Bibcode:1937RSPTA.236..333N. JSTOR 91337. doi:10.1098/rsta.1937.0005
- ^ Carver, Ronald P. The Case Against Statistical Significance Testing. Harvard Educational Review. 1978, 48 (3): 378–399. S2CID 16355113. doi:10.17763/haer.48.3.t490261645281841.
- ^ Ioannidis, John P. A. Why most published research findings are false. PLOS Medicine. 2005, 2 (8): e124. PMC 1182327
- ^ 35.0 35.1 Amrhein, Valentin; Korner-Nievergelt, Fränzi; Roth, Tobias. The earth is flat (p > 0.05): significance thresholds and the crisis of unreplicable research. PeerJ. 2017, 5: e3544. PMC 5502092
- ^ 36.0 36.1 Hojat, Mohammadreza; Xu, Gang. A Visitor's Guide to Effect Sizes. Advances in Health Sciences Education. 2004, 9 (3): 241–9. PMID 15316274. S2CID 8045624. doi:10.1023/B:AHSE.0000038173.00909.f6.
- ^ Hooper, Peter. What is P-value? (PDF). University of Alberta, Department of Mathematical and Statistical Sciences. [November 10, 2019]. (原始内容 (PDF)存档于2020-03-31).
- ^ Pedhazur, Elazar J.; Schmelkin, Liora P. Measurement, Design, and Analysis: An Integrated Approach Student. New York, NY: Psychology Press. 1991: 180–210. ISBN 978-0-805-81063-9.
- ^ Stahel, Werner. Statistical Issue in Reproducibility. Principles, Problems, Practices, and Prospects Reproducibility: Principles, Problems, Practices, and Prospects. 2016: 87–114. ISBN 9781118864975. doi:10.1002/9781118865064.ch5.