- 学习周期:12天
- 学习形式:理论学习 + 练习
- 人群定位:对机器学习有一定的了解,会使用常见的数据分析工具(Numpy,Pandas),了解向量检索工具(faiss)的学习者。
- 先修内容:Python编程语言;编程实践(Pandas);编程实践(Numpy)。
- 难度系数:中
本次课程是由Datawhale推荐系统小组内部成员共同完成,是针对推荐系统小白的一入门课程。学习本课程需要学习者对机器学习有一定的了解,会使用常见的数据分析工具(Numpy,Pandas),了解向量检索工具(faiss)。
本次课程内容的设计参考了项亮老师的《推荐系统实践》、王喆老师的《深度学习推荐系统》以及大量的技术博客,选择了在推荐系统算法发展中比较重要的几个算法作为本次课程的核心内容,对于每个算法都进行了细致的分析以及必要的代码的演示,便于学习者们深刻理解推荐算法的本质。除此之外,每个算法都会在一个完整的数据集上从头到尾的重新把算法实现一遍,以便于学习者们可以快速的使用这些算法。在这些完整的代码中,我们给出了详细的代码注释,尽量让学习者们不会因为看不懂代码而感到烦恼。
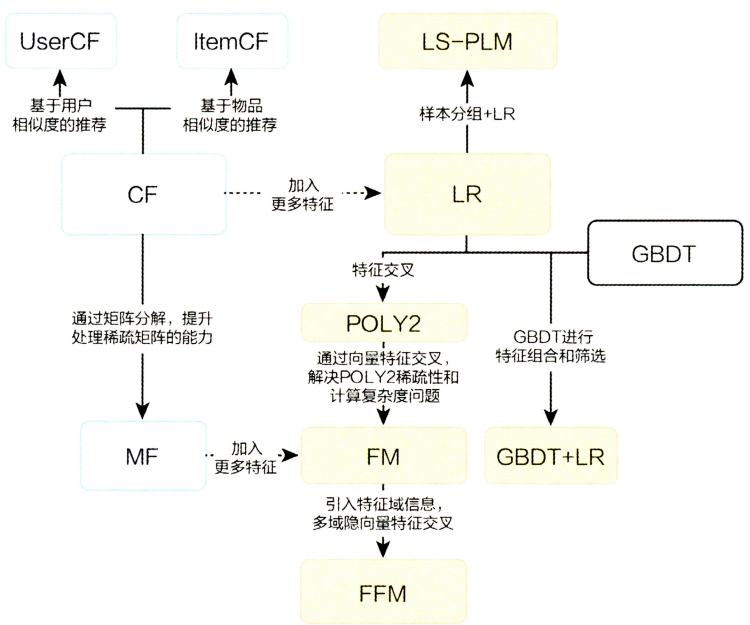
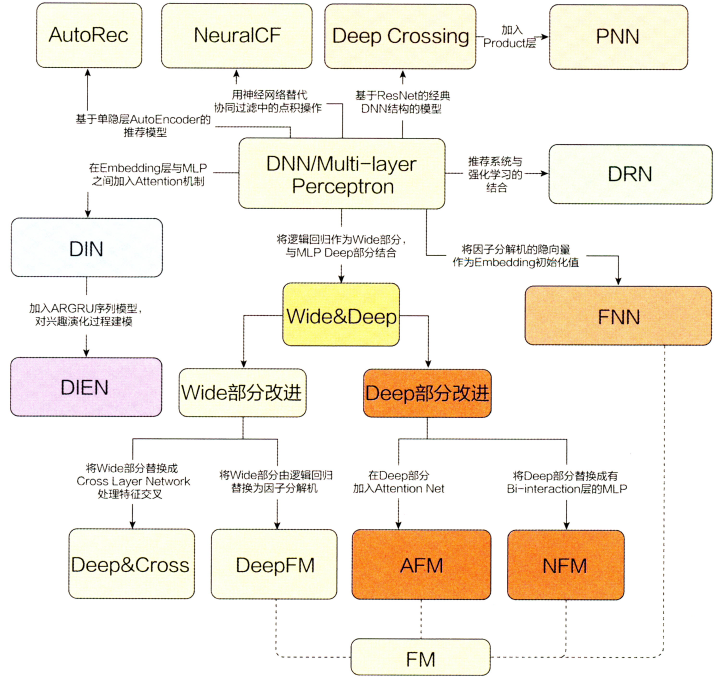
传统推荐系统及深度学习推荐系统的演化关系图(图来自《深度学习推荐系统》)
传统推荐系统:
深度学习推荐系统:
本开源内容的目标是掌握以下算法:
- 协同过滤算法
- 矩阵分解算法
- FM(Factorization Machines)算法
- Wide&Deep
- GBDT+LR
推荐系统组队学习内容汇总:
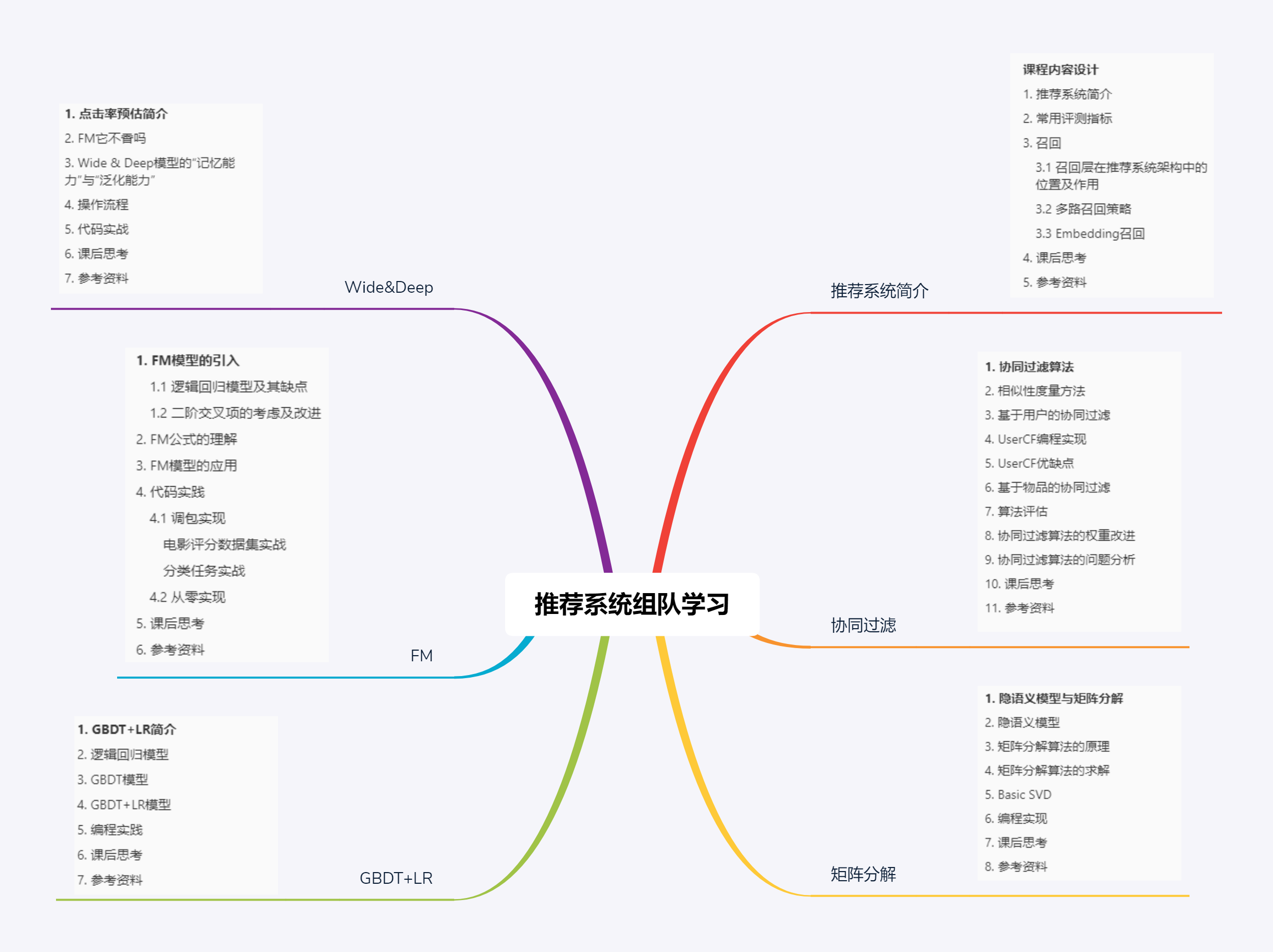
了解推荐系统常用的评测指标、召回的策略和作用等。
掌握协同过滤算法,包括基于用户的协同过滤(UserCF)和基于商品的协同过滤(ItemCF),这是入门推荐系统的人必看的内容,因为这些算法可以让初学者更加容易的理解推荐算法的思想。
掌握矩阵分解和FM算法。
矩阵分解算法通过引入了隐向量的概念,加强了模型处理稀疏矩阵的能力,也为后续深度学习推荐系统算法中Embedding的使用打下了基础。
FM(Factorization Machines)算法属于对逻辑回归(LR)算法应用在推荐系统上的一个改进,在LR模型的基础上加上了特征交叉项,该思想不仅在传统的推荐算法中继续使用过,在深度学习推荐算法中也对其进行了改进与应用。
从深度学习推荐系统的演化图中可以看出Wide&Deep模型处在最中间的位置,可以看出该模型在推荐系统发展中的重要地位,此外该算法模型的思想与实现都比较的简单,非常适合初学深度学习推荐系统的学习者们去学习。
该模型仍然是对LR模型的改进,使用树模型做特征交叉,相比于FM的二阶特征交叉,树模型可以对特征进行深度的特征交叉,充分利用了特征之间的相关性。
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale 以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。 本次数据挖掘路径学习,专题知识将在天池分享,详情可关注Datawhale(二维码在上面)
有关组队学习的开源内容
- team-learning:主要展示Datawhale的组队学习计划。
- team-learning-program:主要存储Datawhale组队学习中“编程、数据结构与算法”方向的资料。
- team-learning-data-mining:主要存储Datawhale组队学习中“数据挖掘/机器学习”方向的资料。
- team-learning-nlp:主要存储Datawhale组队学习中“自然语言处理”方向的资料。
- team-learning-cv:主要存储Datawhale组队学习中“计算机视觉”方向的资料。
- team-learning-rs:主要存储Datawhale组队学习中“推荐系统”方向的资料。
- team-learning-rl:主要存储Datawhale组队学习中“强化学习”方向的资料。