The performance of Spacy's NER is not satisfying. And different behaviors are observed between Spacy and Dispacy. #7493
Comments
|
Hi, this is a good question! The performance difference is due to a bug related to data augmentation for the v3.0.0 models. We added data augmentation with lowercasing to our training for the v2.3 models, but there was a bug in the augmenter and it wasn't applied when we trained the v3.0.0 models. We've fixed the bug and plan to add it back for the v3.1.0 models. In general, if you need the exact same performance, you want to be sure you use the exact same model version like v2.3.0. We try to provide useful pretrained models, but we don't try to guarantee the exact same performance across versions. For instance, we may change or update the underlying datasets or change training parameters between versions. (Actually a number of people complained about the differences between v2.2 and v2.3 models because the tagger confused common nouns and proper nouns more due to the lowercasing. It's impossible to provide a model that's perfect for every use case!) Here my best recommendation would be to use v2.3.x models for processing texts without standard capitalization and reevaluate when v3.1.0 models are released. Or if you train your own model with spacy v3.0.5+, the lowercasing bugs should hopefully be fixed in the provided augmenters. |
|
Not sure if this is related, but there's a regression with the In spaCy 3.0.5 with import spacy
nlp = spacy.load("en_core_web_lg")
doc = nlp("My name is David")
for ent in doc.ents:
print("Found entity:")
print(ent.text, ent.start_char, ent.end_char, ent.label_)
# No entities foundwith spaCy 2.3.2 and import spacy
nlp = spacy.load("en_core_web_lg")
doc = nlp("My name is David")
for ent in doc.ents:
print("Found entity:")
print(ent.text, ent.start_char, ent.end_char, ent.label_)
Found entity:
David 11 16 PERSON |
|
Thanks! I tried version 2.3.0 (https://github.com/explosion/spacy-models/releases/tag/en_core_web_sm-2.3.0) and found it's performance is the same with Dispacy, which is insensitive to the case! Hope this bug can be fixed soon. |
|
For reference, you can see the model version number used in the demo in the displacy demo screenshot above under "Model". This demo is running this exact model underneath, so you should get the same results as with this model and The 3.0.0 test with "David" looks more like a model fluke more than a major regression related to NER or |
|
@adrianeboyd were previous models (like |
|
Yes, the models are always retrained for new minor versions. v2.2, v2.3, v3.0, etc. and sometimes there are multiple compatible model version for a minor version if there are bug fixes or minor changes in model settings/data. The v3 models with configs are not compatible with v2 at all, and vice versa for the v2 models without configs. Whenever the model version number is different ( |
|
This issue has been automatically closed because it was answered and there was no follow-up discussion. |
|
Coming back to this issue, I did a small test with different names and it seems like there's a pattern here. Biblical names (on my small test) are much less likely to be identified on both This is the short test I did, which is comparing non-biblical names (both old and new) with biblical names, on two simple template sentences (tested on spacy version 3.0.5): biblical_names = ["David", "Moses", "God",
"Abraham", "Samuel", "Jacob",
"Isaac", "Jesus", "Matthew",
"John", "Judas","Simon", "Mary"] # Random biblical names
other_names = ["Beyonce", "Ariana", "Katy", # Singers
"Michael", "Lebron", "Coby", # NBA players
"William", "Charles","Ruth", "Margaret","Elizabeth", "Anna", # Most popular (non biblical) names in 1900 (https://www.ssa.gov/oact/babynames/decades/names1900s.html)
"Ronald", "George", "Bill", "Barack", "Donald", "Joe" # Presidents
]
template1 = "My name is {}"
template2 = "This is what God said to {}" # Note that 'God' in theory should also be a named entity.Evaluating recall: from typing import List
import pprint
import spacy
def names_recall(nlp: spacy.lang.en.English, names: List[str], template: str):
"""
Run the spaCy NLP model on the template + name,
calculate recall for detecting the "PERSON" entity
and return a detailed list of detection
:param nlp: spaCy nlp model
:param names: list of names to run model on
:param template: sentence with placeholder for name (e.g. "He calls himself {}")
"""
results = {}
for name in names:
doc = nlp(template.format(name))
results[name] = len([ent for ent in doc.ents if ent.label_ == "PERSON"]) > 0
recall = sum(results.values()) / (len(names)*1.0)
print(f"Recall: {recall:.2f}\n")
return results
name_sets = {"Biblical": biblical_names, "Other": other_names}
templates = (template1, template2)
detailed_results = {}
print("Model name: en_core_web_lg")
for name_set, template in itertools.product(name_sets.items(),templates):
print(f"Name set: {name_set[0]}, Template: \"{template}\"")
results = names_recall(en_core_web_lg, name_set[1], template)
detailed_results[(name_set[0], template)] = results
print("\nDetailed results:")
pprint.pprint(detailed_results)Here are the results for the en_core_web_lg model: Model name: en_core_web_lg Name set: Biblical, Template: "This is what God said to {}" Name set: Other, Template: "My name is {}" Name set: Other, Template: "This is what God said to {}" Detailed results: The Model name: en_core_web_trf Name set: Biblical, Template: "This is what God said to {}" Name set: Other, Template: "My name is {}" Name set: Other, Template: "This is what God said to {}" Detailed results: Not sure how to fix this though. Either the OntoNotes should be fixed (if this is in fact the reason), or additional augmentations should take place before training (e.g., extract a template out of a sentence in OntoNotes, and inject other values for this entity) I would appreciate @adrianeboyd @ines @honnibal's thoughts on this. Thanks for the amazing work! |
|
As a note, the Biblical sections of OntoNotes are annotated for training purposes as having "missing" NER annotation, not as It does make sense to try out things like this, but I'm also not sure whether your comparison is testing what you intended here. :) Michael, Anna, and Ruth appear in the Biblical section and the training data is old enough that Beyonce and Lebron do not occur at all. One suspect is missing lowercase augmentation (there was a bug when we trained v3.0 and the lowercase augmentation was skipped vs. v2.3), and overall it looks like some more general augmentation around proper names (especially to cover newer names that aren't in the old training data) is definitely a good idea! |
|
Thanks @adrianeboyd! Are there any public versions of the spaCy training flow which handles the missing NER annotations? Results on three sentences using the en_core_web_lg model: biblical_names = ["David", "Moses", "Abraham", "Samuel", "Jacob",
"Isaac", "Jesus", "Matthew",
"John", "Judas","Simon", "Mary"] # Random biblical names
other_names = ["Beyonce", "Ariana", "Katy", # Singers
"Michael", "Lebron", "Coby", # NBA players
"William", "Charles","Robert", "Margaret","Frank", "Helen", # Popular (non biblical) names in 1900 (https://www.ssa.gov/oact/babynames/decades/names1900s.html)
"Ronald", "George", "Bill", "Barack", "Donald", "Joe" # Presidents
]
template1 = "My name is {}"
template2 = "And {} said, Why hast thou troubled us?"
template3 = "And she conceived again, a bare a son; and she called his name {}."
name_sets = {"Biblical": biblical_names, "Other": other_names}
templates = (template1, template2, template3)Model name: en_core_web_lg How would you suggest to add augmentation to the spaCy training pipelines? In the work we do on Presidio we extracted template sentences from OntoNotes, injected fake entities instead of the original entities and trained the model on more data this way. Is this something you would consider as a contribution to spaCy? |
|
This is also speculation to some degree, but I think another problem is that you rarely have first names in isolation in the training data, so it ends up learning that And without doing a lot of debugging I can't entirely rule out that something is going wrong with the training, either. I think that training with partial annotation is something that we do internally more than users typically do, so it's possible we've missed a subtle bug. We have a corpus augmentation option in our corpus reader and the augmenters are here: There are docs with some examples here: https://spacy.io/usage/training#data-augmentation-custom We haven't done a lot of testing related to what kinds/amount of augmentation works best or how to evaluate it well. So far our augmentation just lowers our scores on our dev sets because the training texts are slightly less similar to the training sets than in the original. We also don't currently have any examples for augmentations that change the number of tokens. We also wanted to have some whitespace augmentation, but our initial attempt with random augmentation caused problems for the NER annotation (which shouldn't start or end with whitespace) and we stopped working on it at some point. I think the trickiest part would be aligning all the other annotation layers, so if you're modifying names in a way that changes the number of tokens or the internal structure of the name, you'd also have to adjust the parse and tags, if present. On the other hand, lots of people only work on NER models, so an augmenter that is restricted to NER-only training data could still be quite useful. In general, contributions are welcome! We'd have to discuss a bit about whether particular augmenters make sense in the core library, potentially in a separate package that we manage to some degree, or as a "spaCy universe" contribution where we're happy to advertise it but don't maintain the package. |
|
Thanks @adrianeboyd. Very interesting points. I'll definitely look into the corpus augmentation option, and agree this is difficult to evaluate as the datasets themselves were not augmented prior to being labeled. FYI, a similar evaluation on two Flair models show that the a model trained on OntoNotes achieves significantly lower results on this test. The CONLL based model actually does pretty well. CONLL-03 based model results: OntoNotes based model results: Hope this helps in any way :) |
|
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs. |
|
@omri374: I just had another look at this and I think you were exactly right about the missing entity annotation in some sections of OntoNotes (in particular the Biblical sections) causing problems in the v3 models. I just tracked down bugs in the augmenters causing missing entity annotation to be converted to Now to retrain the English pipelines and see what happens... |
|
With the draft The draft |
|
After looking into this some more, it appears that training a shared We're still looking into exactly why this is happening, but as an initial improvement we've added silver NER annotation to the sections where NER is missing and retrained the pipeline, with 100% recall for the examples above and equivalent overall performance: We'll plan to publish these models as model version v3.4.1, probably at the same time as spacy v3.4.2 is released so we can include all the details in the release notes. |
|
The new models (model version v3.4.1) have been published alongside spacy v3.4.2. They will be compatible with any spacy v3.4.x release. |
|
Thank you @adrianeboyd! |
|
This issue has been automatically closed because it was answered and there was no follow-up discussion. |
|
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs. |
When I use the dispacy to do NER for the sentence
"drawing from mutualism, mikhail bakunin founded collectivist anarchism and entered the international workingmen's association, a class worker union later known as the first international that formed in 1864 to unite diverse revolutionary currents."
I get the result
However when I use the offline version, I only get two named entities, which is far from satisfactory.
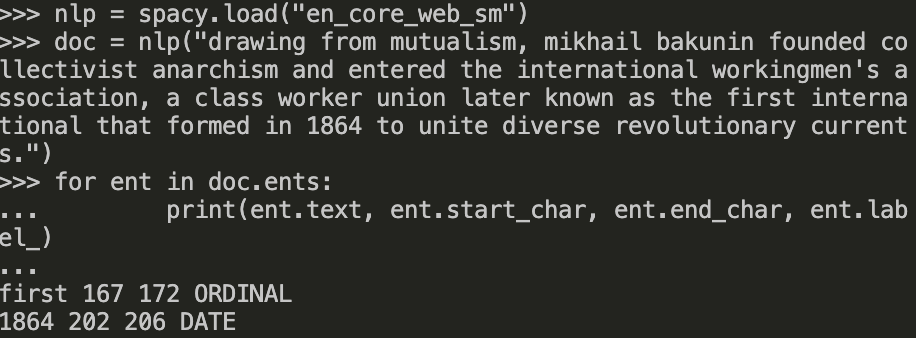
Similar observations appear in other sentences.
The package version is 3.0.0, which is different from Dispacy's 2.3.0, However, I believe the more recent version should not yield a worse performance.
Did I miss something, such as preprocessing? Thanks in advance!
The text was updated successfully, but these errors were encountered: