tf.data.Dataset .map().batch() pattern is not matched to use fused implementation. #53572
Comments
|
@mcourteaux , |
|
No, I'm most definitely not. This was a fresh build from master branch from yesterday. Idk why the script that gives the TF version gives 1.12. It's most definitely wrong. I moved to TF 2 years ago. Note that that is the GIT_VERSION. Instead, |
|
@mcourteaux , |
|
First a little frustration: @tilakrayal I get the sensation you are not paying attention. How does Google hope to get contributions to a project if all of the useful feedback is dismissed as being either wrong or nobody paying attention? It's frustrating that I lost around 2 hours identifying this problem, and then one more hour making a nice MWE that demonstrates the problem cleanly. Compare my three hour effort, to flow of this issue... I'll tag people who know what's going on: @jsimsa, @aaudiber. You somehow managed to make a notebook with the code from the linked issue, not mine. There is no error message, with my code. I showed you how the Happy new year! |
|
Hi @mcourteaux, thank you for the detailed repro and sorry for the initial response. I will have someone on the tf.data team take a closer look. |
|
@wilsingosti is taking a look |
|
The |
|
IIUC, the |
|
@wilsingosti Thanks for checking this. I'm wondering why not most Dataset implementations use the |
|
Yes, it would be useful in general. AFAIK, it has just not been prioritized so far. I will try to do this for |
System information
Describe the current behavior
combining
tf.data.Dataset.map()with.batch()does not use the fused BatchAndMap implementation.Describe the expected behavior
It does use the fused implementation. Currently, it's only possible to use the fused implementation when using the deprecated
experimental.map_and_batch()transformation.Contributing
Standalone code to reproduce the issue
Other info / logs
Option 1:
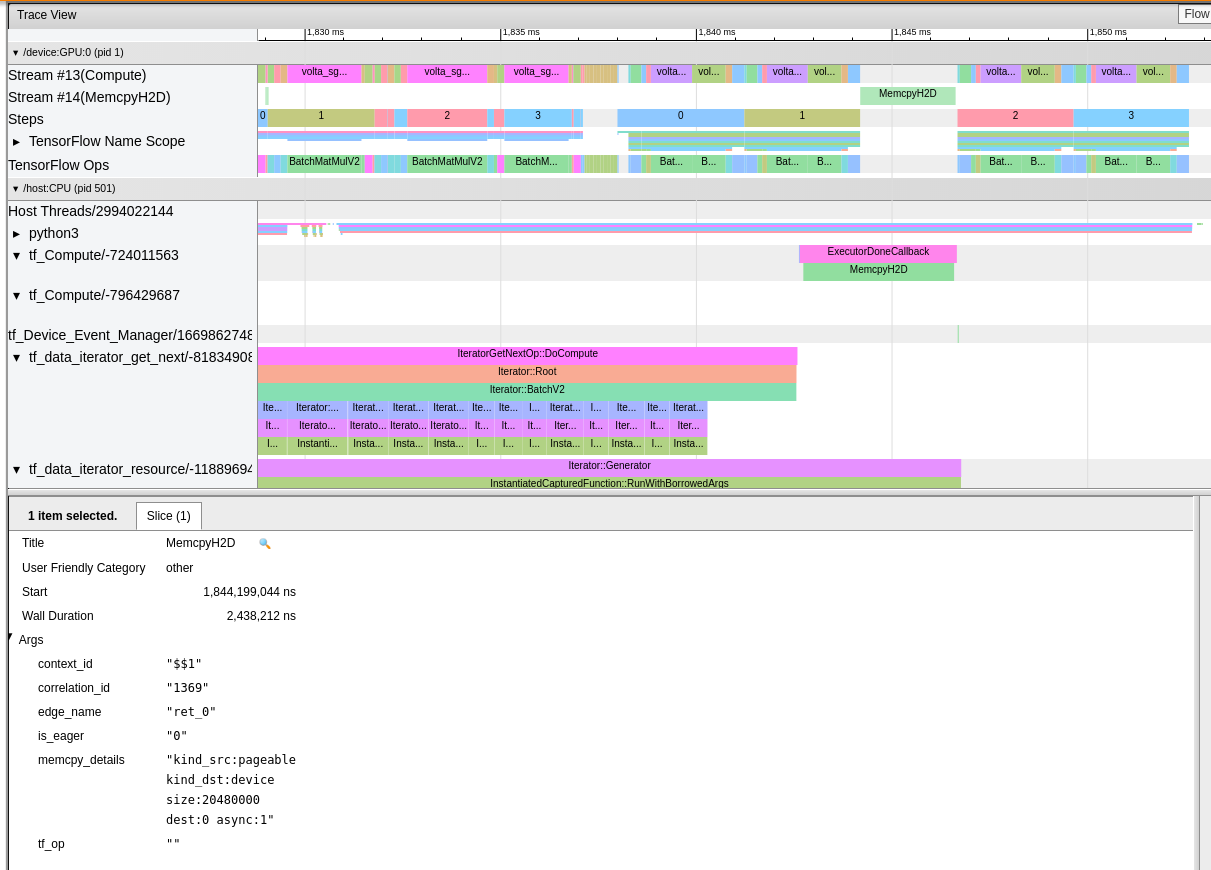
Symptoms:
Iterator::FlapMapandIterator::BatchV2stacked on top of each other.Option 2:
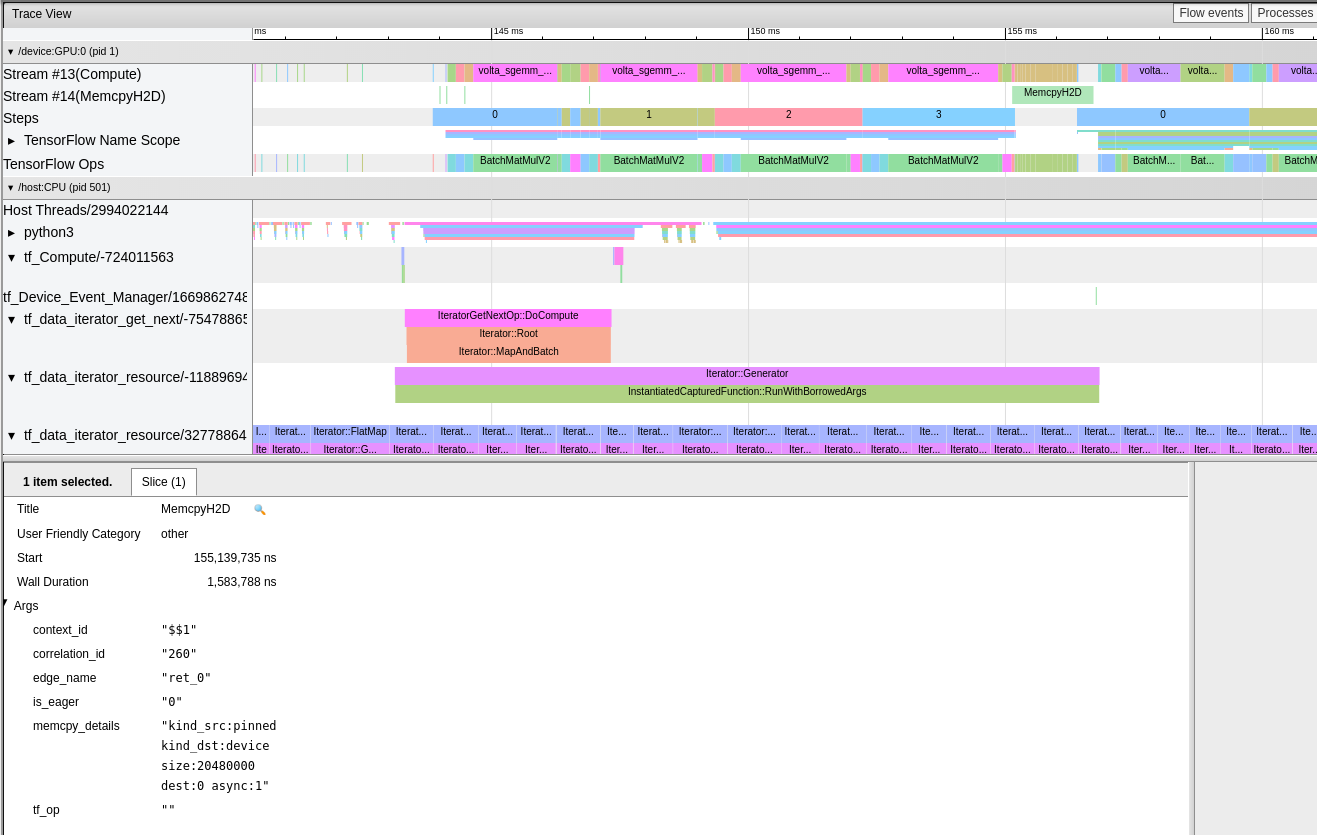
Evidence:
The whole deal about pinned memory is to allow parallel data upload and kernel computations. So the dataset needs to be produced into pinned host memory, which then can be uploaded asynchronously by the driver without an extra copy. See #43905 (comment) and #43905 (comment) and:
tensorflow/tensorflow/core/kernels/data/experimental/map_and_batch_dataset_op.cc
Line 522 in 40e9b53
This is a follow up on #43905.
The text was updated successfully, but these errors were encountered: