Translation lookaside buffer

TLB (do inglês Translation Lookaside Buffer) é um dispositivo de hardware implementado a partir de uma pequena memória associativa que fica integrada na Unidade de Gerenciamento de Memória de um processador. Destina-se a facilitar a tradução de endereços lineares em endereços físicos, evitando a consulta à tabela de páginas localizada na memória[1].
Introdução
Visando o compartilhamento seguro e eficiente da memória entre diferentes programas ao mesmo tempo, foi desenvolvida a memória virtual que funciona basicamente gerando endereços lógicos de memória, que são posteriormente traduzidos para endereços físicos pela MMU ou unidade de gerenciamento de memória[2]. Esta tradução é feita percorrendo uma tabela de páginas que liga o endereço virtual com o endereço físico da memória[2]. Esta tradução acaba gerando um grande número de acessos a memória (três acessos em média)[2], de forma que surge a necessidade de utilizar algum tipo de mecanismo para agilizar o processo, e aqui entra a finalidade da Translation Lookaside Buffer ou TLB. Quando a memória virtual é acessada a CPU busca na TLB pelo número da página virtual que será acessada, caso encontre (Hit) será usada a entrada da tabela de páginas (Page Table Entry ou PTE) armazenada na TLB, caso não encontre (Miss) o tratador de interrupção buscara uma maneira de contornar a falta deste endereço na TLB.
Em resumo TLB opera com o princípio similar ao da memória cache, reduzindo acessos a memória principal sempre que possível.
Estrutura
A estrutura básica de uma TLB é formada pelos seguintes campos:
| Tag | Detalhes |
|---|---|
| VPN | Traduzido como Virtual Page Number, armazena o número da página virtual da entrada[1] |
| PFN | Traduzido como Physical Frame Number, armazena o número do frame da memória principal[1] |
| VALID | Bit de validação, informa se é uma entrada válida[1] |
| PROT | Bit de proteção, determina permissões para a entrada (Leitura, Escrita, Execução)[1] |
| ASID | Bit de identificação, utilizado para resolver conflitos ocasionados por troca de contextos[1] |

Outros campos podem ser implementados dependendo da arquitetura e da maneira como esta é implementada em hardware e tratada em software.
O TLB incluído no processador Intel i486DX era constituído por uma memória associativa em grupos de 4 vias (4-way) com 32 posições[3].
Tratamento de interrupção
O tratamento de interrupções (falhas ao buscar entradas nas TLB) é realizado a partir de duas formas diferentes. Dependendo da arquitetura da CPU ocorrerá por hardware ou por software.
Hardware: A CPU automaticamente busca pela tabela de páginas uma entrada (PTE) válida para o endereço virtual acessado. Quando a PTE não for encontrada é gerado um “Page Fault Exception”. Uma vez assinalada a exceção, o sistema operacional fica encarregado de resolver a falta da página.[4]
Software: A CPU informa o sistema operacional não ter encontrado a entrada. Então este ativa seu tratador de interrupções (TLB miss handler) e inicia uma busca em software pela página faltando, se uma entrada válida for encontrada, a nova tradução é inserida da TLB, se não for localizada o tratador de interrupção passada a tarefa para o PFH (Page Fault Handler) que deverá buscar pela página correta[5].
Seja por hardware ou por software, o resultado será uma busca na tabela de páginas e se a entrada for encontrada e validada, a TLB será atualizada com a nova tradução. A maioria das CPUs baseadas em CISC como a x86, realizam tratamento por hardware enquanto tecnologias baseadas em RISC como ARM o fazem por software.
O tratamento por hardware normalmente oferece maior agilidade no tratamento, porém sem a flexibilidade do tratamento por software. Por vezes perde-se performance por má compatibilidade do hardware com as necessidades do sistema operacional. Desta forma já vem sendo feito trabalhos positivos em desenvolver um técnica híbrida para o tratamento de interrupções, como na arquitetura IA-64.
Política de substituição
Todo sistema que opera com o princípio de uma cache de dados busca fornecer o maior número possível de dados, porém, visto o pequeno espaço de armazenamento, definir que dados armazenar torna-se crucial para seu bom desempenho. A TLB precisa armazenar aquelas entradas para tabela de página que estejam sendo mais utilizadas, logo, quando necessário incluir uma nova entrada, é necessário substituir ou sobrescrever a entrada.
Para definir qual entrada será sobrescrita existem diferentes tipos de política de substituição, baseadas em algoritmos como LRU (Least Recently Used), que visa descartar os registros que estão a mais tempo sem serem utilizados ou NRU (Not Recently Used) que descarta registros que tenham ultrapassado um período longo (pré-definido) que não tenham sido reutilizados.
Políticas de substituição, assim como tratamento de interrupção, podem ser implementados em hardware e software. Soluções em hardware tendem a utilizar políticas mais simples como NRU, enquanto políticas de software optam por técnicas como LRU e outros modelos mais complexos.
A política de substituição funciona em alinhamento com o tratamento de interrupção, de modo que se este for empregado em hardware, a política de substituição obrigatoriamente deve ser implementada em hardware. Caso contrário, tratamentos por software, mais flexíveis, permitem políticas tanto de hardware quanto de software[4].
Troca de contexto
Outra situação que precisa ser prevista em sistemas com a implementação da TLB são as trocas de contexto. Quando mais de um processo estão sendo executados, a CPU deve dividir seus ciclos de clock entre estes, de modo que todos os processos possam ser concluído no menor tempo possível. A alternância destes processos na CPU da-se o nome de troca de contexto.
Esta ação pode gerar algumas situações possivelmente complicadas, como o uso de entradas incorretas e o descarte de entradas úteis. Quando uma troca de contexto é realizada, as entradas armazenadas na TLB são pouco úteis, pois referem-se a endereços de memória usados pelo processo anterior, porém a CPU não "sabe" disso, logo é necessário ter um cuidado especial para evitar que entradas de processos anteriores sejam utilizadas incorretamente. [1]
Para ilustrar como estas situações podem ocorrer observemos o seguinte exemplo. Temos o processo P1 que teve sua 10º página mapeada para o frame 100 da memória principal, então temos uma troca de contexto com o processo P2 e na 10º página deste processo foi mapeado o frame 170. Possuindo ambas entradas na TLB a situação seria a seguinte:
| VPN | PFN | VALID | PROT |
|---|---|---|---|
| 10 | 100 | 1 | rwx |
| - | - | - | - |
| 10 | 170 | 1 | rwx |
| - | - | - | - |
Na situação ilustrada o VPN 10 pode ter seu PFN traduzido tanto para 100 como para 170, logo, sem algum tipo de controle, não há como diferenciar uma entrada da outra. Uma das maneiras para solucionar este problema é a utilização o campo ASID (Address Space Identifier), um pequeno campo geralmente de 8 bits, este campo tem um funcionamento similar ao PID (Process Identifier) utilizado pelo sistema operacional, e tem sua finalidade ajudar o hardware a verificar a quais processos cada entrada pertence.
| VPN | PFN | VALID | PROT | ASID |
|---|---|---|---|---|
| 10 | 100 | 1 | rwx | 1 |
| - | - | - | - | - |
| 10 | 170 | 1 | rwx | 2 |
| - | - | - | - | - |
TLB multinível
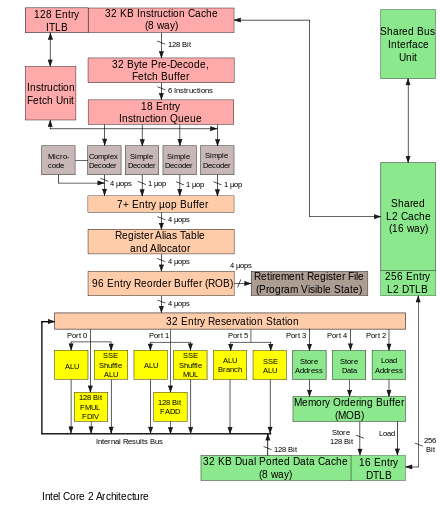
Outra característica similar ao que se encontra na memória cache principal da CPU é a implementação de múltiplos níveis de armazenamento. Tipicamente os processadores atuais implementam três níveis em sua memória cache[6], referenciadas geralmente por L + nível (L1, L2, L3,...) , algumas arquiteturas como Intel Nehalem, implementam TLBs de dois níveis.
No caso da arquitetura Nehalem a organização destes níveis funciona com um nível L1 DTLB (Chamado também de micro-TLB), uma pequena TLB utilizada apenas para leituras, constituído com 16 entradas para páginas de 4KB e 16 entradas para páginas maiores, cada bloco de 16 entradas utilizando uma associação 4-way.[7]
Para o nível 2 ou L2 DTLB, a configuração é de 256 entradas de 4KB e 32 entradas para páginas maiores (2MB/4MB), e ambos os blocos com associação 4-way. Quando ocorre um TLB miss no L1 DTLB, a CPU automaticamente busca na L2 DTLB, antes de iniciar outras técnicas para o tratamento de interrupção pelo TLB miss[7].
Ver também
- ↑ a b c d e f g Arpaci-Dusseau (2014). «Paging: Faster Translations» (PDF). Consultado em 20 de maio de 2015
- ↑ a b c Sistemas Operacionais Modernos. [S.l.: s.n.] 1999
|nome1=sem|sobrenome1=em Authors list (ajuda) - ↑ «Use of Translation Look-aside Buffer (TLB) in 80386». Consultado em 24 de maio de 2015
- ↑ a b Larry Snyder (1998). «Translation Lookasided Buffer» (PDF). Consultado em 20 de maio de 2015
- ↑ Por Stephane Eranian e David Mosberger (8 de novembro de 2002). «Virtual Memory in the IA-64 Linux Kernel». Consultado em 20 de maio de 2015
- ↑ Margaret Rouse (2013). «What is cache memory». Consultado em 24 de maio de 2015
- ↑ a b David Kanter (2 de abril de 2008). «Inside Nehalem: Intel's Future Processor and System». Consultado em 24 de maio de 2015