Entrepôt de données
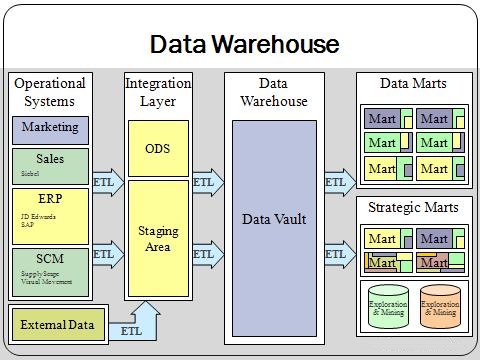
Le terme entrepôt de données[1] ou EDD (ou base de données décisionnelle ; en anglais, data warehouse ou DWH) désigne une base de données utilisée pour collecter, ordonner, journaliser et stocker des informations provenant de base de données opérationnelles[2] et fournir ainsi un socle à l'aide à la décision en entreprise.
Définition et construction
[modifier | modifier le code]Un entrepôt de données est une base de données regroupant une partie ou l'ensemble des données fonctionnelles d'une entreprise. Il entre dans le cadre de l'informatique décisionnelle ; son but est de fournir un ensemble de données servant de référence unique, utilisée pour la prise de décisions dans l'entreprise par le biais de statistiques et de rapports réalisés via des outils de reporting. D'un point de vue technique, il sert surtout à 'délester' les bases de données opérationnelles des requêtes pouvant nuire à leurs performances.
D'un point de vue architectural, il existe deux manières de l'appréhender :
- l'architecture « de haut en bas » : selon Bill Inmon, l'entrepôt de données est une base de données au niveau détail, consistant en un référentiel global et centralisé de l'entreprise. En cela, il se distingue du Datamart, qui regroupe, agrège et cible fonctionnellement les données ;
- l'architecture « de bas en haut » : selon Ralph Kimball, l'entrepôt de données est constitué peu à peu par les Datamarts de l'entreprise, regroupant ainsi différents niveaux d'agrégation et d'historisation de données au sein d'une même base.
La définition la plus communément admise est un mélange de ces deux points de vue. Le terme « data warehouse » englobe le contenant et le contenu : il désigne d'une part la base détaillée qui est la source de données à l'origine des Datamarts, et d'autre part l'ensemble constitué par cette base détaillée et ses Datamarts. De la même manière, les méthodes de conception actuelles prennent en compte ces deux approches, privilégiant certains aspects selon les risques et les opportunités inhérents à chaque entreprise.
Principe de fonctionnement
[modifier | modifier le code]Intégration
[modifier | modifier le code]Dans les faits, les données alimentant l'entrepôt de données sont hétérogènes, issues de différentes applications de production, voire de fichiers dits « plats » (fichiers Excel, fichiers texte, XML...). Il s’agit alors de les intégrer, de les homogénéiser et de leur donner un sens unique compréhensible par tous les utilisateurs. La transversalité recherchée sera d’autant plus efficace que le système d’information sera réellement intégré dans sa globalité. Cette intégration nécessite notamment :
- une forte activité de normalisation et de rationalisation, orientée vers la qualité ;
- une bonne gestion des référentiels, incluant une vérification constante de leur intégrité ;
- une parfaite maîtrise de la sémantique et des règles de gestion des métadonnées manipulées.
La problématique de l'intégration repose sur la standardisation de données internes à l'entreprise, mais aussi des données externes (provenant par exemple de clients ou de fournisseurs).
Ce n’est qu’au prix d’une intégration poussée que l’on peut offrir une vision homogène et véritablement transverse de l’entreprise. Ceci suppose que le système d’information de l’entreprise en amont soit bien structuré, bien maîtrisé, et bénéficie déjà d’un niveau d’intégration suffisant. Si tel n'est pas le cas, la mauvaise qualité des données peut empêcher la mise en œuvre de l'entrepôt de données.
Historisation
[modifier | modifier le code]L'historisation d'un Datawarehouse repose sur le principe de conservation des données (ou de non-volatilité des données). Afin de conserver la traçabilité des informations et des décisions prises, les données une fois entrées dans l'entrepôt sont stables, en lecture seule, non modifiables par les utilisateurs. Une même requête lancée plusieurs fois à différents moments doit ainsi restituer les mêmes résultats. Dès qu’une donnée est qualifiée pour être introduite dans l'entrepôt de données, elle ne peut donc plus être altérée, modifiée ou supprimée (jusqu'à un certain délai de purge). Elle devient, de fait, partie intégrante de l’historique de l’entreprise.
Le principe de non-volatilité tranche avec la logique des systèmes de production, qui bien souvent remettent à jour les données par « annule et remplace » à chaque nouvelle transaction. Chaque donnée collectée se voit affecter une date ou un numéro de version pour éviter de recouvrir une information déjà présente dans la base de données, et permettre de suivre son évolution au cours du temps. Il y a de cette manière conservation de l'historique.
D’un point de vue fonctionnel, cette propriété permet de suivre dans le temps l’évolution des indicateurs et de réaliser des analyses comparatives (par exemple, les ventes d'une année sur l'autre). De ce fait, dans un entrepôt de données, un référentiel de temps unique est nécessaire.
Organisation fonctionnelle
[modifier | modifier le code]L'entrepôt de données intègre au sein d'une même base les informations provenant de multiples applications opérationnelles. On passe ainsi d’une vision verticale de l’entreprise, dictée par des contraintes techniques, à une vision transversale, dictée par le besoin métier, qui permet de croiser fonctionnellement les informations. L’intérêt de cette organisation est de disposer de l’ensemble des informations utiles sur un sujet le plus souvent transversal aux structures fonctionnelles (services) de l’entreprise. On dit que l'entrepôt de données est orienté « métier », en réponse aux différents métiers de l’entreprise dont il prépare l’analyse. Lorsque l'entrepôt de données est transverse on parle alors de « Datawarehouse », lorsque l'entrepôt de donnée est spécialisé dans un domaine métier (Finance, Achats, Production, etc.), on parlera alors plutôt de « Datamart ».
D'un point de vue conceptuel, les données d'un Data warehouse sont interprétables sous forme d'indicateurs répartis selon des axes (ou dimensions) : par exemple, le nombre de clients (indicateur) réparti par jour de vente, magasin ou segment de clientèle (axes). Techniquement, la modélisation de l'entrepôt de données peut matérialiser cette organisation sous forme de tables de fait ou et de tables de référentiel.
Structure de données
[modifier | modifier le code]L'entrepôt de données a une structure de données qui peut en général être représentée par un modèle de données normalisé 3FN (3NF (en)) pour les données de détail et/ou en étoile ou en flocon pour les données agrégées et ce dans un SGBD relationnel (notamment lorsqu'il s'agit de données élémentaires ou unitaires non agrégées). La traduction technique de ce modèle se fait souvent au sein d'un cube OLAP.
L'entrepôt de données est conçu pour contenir les données en adéquation avec les besoins de l’organisation, et répondre de manière centralisée à tous les utilisateurs. Il n’existe donc pas de règle unique en matière de stockage ou de modélisation.
Ainsi, ces données peuvent donc être conservées :
- de préférence, sous forme élémentaire et détaillée (exemple : pour une banque, chaque opération sur chaque compte de chaque client) si la volumétrie le permet. Les données élémentaires présentent des avantages évidents (profondeur et niveau de détail, possibilité d'appliquer de nouveaux axes d'analyse et même de revenir a posteriori sur le « passé ») mais représentent un plus grand volume et nécessitent donc des matériels plus performants.
- éventuellement, sous forme agrégée selon les axes ou dimensions d'analyse prévus (mais ces agrégations sont plutôt réalisées dans les datamarts que dans les entrepôts de données proprement dits). Les données agrégées présentent d'autres avantages (facilité d'analyse, rapidité d'accès, moindre volume). Par contre, il est impossible de retrouver le détail et la profondeur des indicateurs une fois ceux-ci agrégés : on prend le risque de figer les données selon une certaine vue avec les axes d'agrégation retenus, et de ne plus pouvoir revenir sur ces critères si l'on n'a pas conservé le détail (par exemple, si l'on a agrégé les résultats par mois, il ne sera plus possible de faire une analyse par journée).
Autour de l'entrepôt de données
[modifier | modifier le code]En amont
[modifier | modifier le code]En amont de l'entrepôt de données se place toute la logistique d'alimentation des données de l'entrepôt :
- extraction des données de production, transformations éventuelles et chargement de l'entrepôt (c'est l'ETL ou Extract, Transform and Load ou encore datapumping).
- au passage les données sont épurées ou transformées par :
- un filtrage et une validation des données (les valeurs incohérentes doivent être rejetées)
- un codage (une donnée représentée différemment d'un système de production à un autre impose le choix d'une représentation unique pour les futures analyses)
- une synchronisation (s'il y a nécessité d'intégrer en même temps ou à la même « date de valeur » des événements reçus ou constatés de manière décalée)
- une certification (pour rapprocher les données de l'entrepôt des autres systèmes « légaux » de l'entreprise comme la comptabilité ou les déclarations réglementaires).
Cette alimentation de l'entrepôt de données se base sur les données sources issues des systèmes transactionnels de production, sous forme de :
- compte-rendu d'événement ou compte-rendu d'opération : c'est le constat au fil du temps des opérations (achats, ventes, écritures comptables...), le film de l'activité de l'entreprise ou flux ;
- compte-rendu d'inventaire ou compte-rendu de stock : c'est l'image photo prise à un instant donné (à une fin de période : mois, trimestre...) de l'ensemble du stock (clients, contrats, commandes, encours...).
La mise en place d'un système d'alimentation fiable de l'entrepôt de données est souvent le poste budgétaire le plus coûteux dans un projet d'informatique décisionnelle.
En aval
[modifier | modifier le code]En aval de l'entrepôt de données (et/ou des datamarts) se place tout l'outillage de restitution et d'analyse des données (informatique décisionnelle) :
- outils de requêtage ou de reporting ;
- cubes ou hypercubes multidimensionnels ;
- data mining.
La conception d'entrepôts de données [3] est donc un processus en perpétuelle évolution. Sous cet angle, on peut finalement voir l'entrepôt de données comme une architecture décisionnelle capable à la fois de gérer l'hétérogénéité et le changement et dont l'enjeu est de transformer les données en informations directement exploitables par les utilisateurs du métier concerné.
Comparatif entre les bases de données de l'entreprise
[modifier | modifier le code]| Caractéristique | Base de données de production | Data warehouses | Datamarts |
|---|---|---|---|
| Opération | gestion courante, production | référentiel, analyse ponctuelle | analyse récurrente, outil de pilotage, support à la décision |
| Modèle de données | entité/relation | 3NF, étoile, flocon | étoile, flocon |
| Normalisation | fréquente | maximum | rare (redondance d'information) |
| Données | actuelles, brutes, détaillées | historisées, détaillées | historisées, agrégées |
| Mise à jour | immédiate, temps réel | souvent différée, périodique | souvent différée, périodique |
| Niveau de consolidation | faible | faible | élevé |
| Perception | verticale | transverse | horizontale |
| Opérations | lectures, insertions, mises à jour, suppressions | lectures, insertions, mises à jour | lectures, insertions, mises à jour, suppressions |
| Taille | en gigaoctets | en téraoctets | en gigaoctets |
Ces différences tiennent au fait que les entrepôts permettent des requêtes qui peuvent être complexes et qui ne reposent pas nécessairement sur une table unique. On peut résumer les conséquences de la transformation d'un Data warehouse en Datamart comme suit : un gain de temps de traitement et une perte de puissance d'utilisation.
Exemples de requêtes OLAP :
- Quel est le nombre de paires de chaussures vendues par le magasin « OnVendDesChaussuresIci » en mai 2003 ET Comparer les ventes avec le même mois de 2001 et 2002
- Quelles sont les composantes des machines de production ayant eu le plus grand nombre d’incidents imprévisibles au cours de la période 1992-97 ?
Les réponses aux requêtes OLAP peuvent prendre de quelques secondes à plusieurs minutes, voire plusieurs heures.
Histoire
[modifier | modifier le code]Le concept de data warehousing remonte à la fin des années 1980 [4] lorsque les chercheurs d'IBM Barry Devlin et Paul Murphy ont développé le « business data warehouse ». Essentiellement, le concept d'entreposage de données visait à fournir un modèle architectural pour le flux de données des systèmes opérationnels aux environnements d'aide à la décision.
Le concept a tenté de répondre aux différents problèmes associés à ce flux, principalement les coûts élevés qui y sont associés. En l'absence d'une architecture d'entreposage de données, une énorme quantité de redondance était nécessaire pour prendre en charge plusieurs environnements d'aide à la décision. Dans les grandes entreprises, il était courant que plusieurs environnements d'aide à la décision fonctionnent de manière indépendante. Bien que chaque environnement servait des utilisateurs différents, ils nécessitaient souvent une grande partie des mêmes données stockées. Le processus de collecte, de nettoyage et d'intégration des données provenant de diverses sources, généralement des systèmes opérationnels existants à long terme (souvent appelés systèmes hérités), était en partie répliqué pour chaque environnement. De plus, les systèmes opérationnels étaient fréquemment réexaminés au fur et à mesure de l'émergence de nouveaux besoins d'aide à la décision. Souvent, les nouvelles exigences nécessitaient la collecte, le nettoyage et l'intégration de nouvelles données à partir de « datamarts » conçues pour un accès facile par les utilisateurs.
De plus, avec la publication de The IRM Imperative (Wiley & Sons, 1991) par James M. Kerr, l'idée de gérer et d'attribuer une valeur monétaire aux ressources de données d'une organisation, puis de déclarer cette valeur en tant qu'actif dans un bilan est devenue populaire. Dans le livre, Kerr a décrit un moyen de remplir des bases de données de domaines à partir de données dérivées de systèmes axés sur les transactions pour créer une zone de stockage où les données récapitulatives pourraient être davantage exploitées pour éclairer la prise de décision des dirigeants. Ce concept a servi à promouvoir une réflexion plus approfondie sur la manière dont un Data Warehouse pourrait être développé et géré de manière pratique au sein de toute entreprise.
Principaux développements au cours des premières années de l'entreposage de données :
- Années 1960 – General Mills et Dartmouth College, dans le cadre d'un projet de recherche conjoint, développent les termes dimensions et facts[5].
- Années 1970 – ACNielsen et IRI fournissent des magasins de données dimensionnelles pour les ventes au détail.
- Années 1970 – Bill Inmon commence à définir et à discuter du terme Data Warehouse.[réf. nécessaire]
- 1975 – Sperry Univac lance MAPPER (Maintain, Prepare, and Produce Executive Reports), un système de gestion de base de données et de reporting qui inclut le premier 4GL au monde. Il s'agit de la première plate-forme conçue pour la construction de centres d'information (un précurseur de la technologie contemporaine de Data Warehouse).
- 1983 – Teradata introduit l'ordinateur de base de données DBC/1012 spécialement conçu pour l'aide à la décision [6].
- 1984 – Metaphor Computer Systems, fondé par David Liddle et Don Massaro, publie un package matériel/logiciel et une interface graphique permettant aux utilisateurs professionnels de créer un système de gestion de base de données et d'analyse.
- 1985 - Sperry Corporation publie un article (Martyn Jones et Philip Newman) sur les centres d'information, où ils introduisent le terme Data Warehouse MAPPER dans le contexte des centres d'information.
- 1988 – Barry Devlin et Paul Murphy publient l'article « An architecture for a business and information system » où ils introduisent le terme « business data warehouse »[7].
- 1990 – Red Brick Systems, fondée par Ralph Kimball, lance Red Brick Warehouse, un système de gestion de base de données spécialement conçu pour l'entreposage de données.
- 1991 - James M. Kerr, auteurs de The IRM Imperative, qui suggère que les ressources de données pourraient être déclarées comme un actif dans un bilan, renforçant l'intérêt commercial pour la création d'entrepôts de données.
- 1991 – Prism Solutions, fondée par Bill Inmon, présente Prism Warehouse Manager, un logiciel de développement d'un Data Warehouse.
- 1992 – Bill Inmon publie le livre Building the Data Warehouse[8].
- 1995 – Le Data Warehousing Institute, une organisation à but lucratif qui promeut l'entreposage de données, est fondé.
- 1996 – Ralph Kimball publie le livre The Data Warehouse Toolkit[9].
- 2000 - Dan Linstedt publie dans le domaine public la modélisation Data Vault, conçue en 1990 comme une alternative à Inmon et Kimball pour fournir un stockage historique à long terme des données provenant de plusieurs systèmes opérationnels, en mettant l'accent sur le traçage, l'audit et la résilience au changement du modèle de données source.
- 2008 - Bill Inmon, avec Derek Strauss et Genia Neushloss, publie « DW 2.0: The Architecture for the Next Generation of Data Warehousing », expliquant son approche descendante de l'entreposage de données et forgeant l'expression terme data-warehousing 2.0.
- 2012 – Bill Inmon développe et fait connaître la technologie publique sous le nom de « textual disambiguation ». La désambiguïsation textuelle applique le contexte au texte brut et reformate le texte brut et le contexte dans un format de base de données standard. Une fois que le texte brut est passé à travers la désambiguïsation textuelle, il peut être facilement et efficacement accessible et analysé par la technologie de business intelligence standard. La désambiguïsation textuelle est accomplie par l'exécution d'ETL textuel. La désambiguïsation textuelle est utile partout où du texte brut est trouvé, comme dans les documents, Hadoop, les e-mails, etc.
Notes et références
[modifier | modifier le code]- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Data warehouse » (voir la liste des auteurs).
- Alain Venot, Anita Burgun et Catherine Quantin, Informatique Médicale, e-Santé – Fondements et applications, Springer Science & Business, (lire en ligne).
- Isabelle Comyn-Wattiau, Jacky Akoka, Les bases de données, PUF, Que sais-je?, 978-2130533139, chap. ix Les bases de données décisionnelles, 2003.
- Les étapes de conception d'un datawarehouse [1].
- « The Story So Far » [archive du ], (consulté le )
- Kimball 2013, pg. 15
- (en) Paul Gillin, « Will Teradata revive a market? », Computer World, , p. 43, 48 (lire en ligne, consulté le )
- Devlin et Murphy, « An architecture for a business and information system », IBM Systems Journal, vol. 27, , p. 60–80 (DOI 10.1147/sj.271.0060)
- Bill Inmon, Building the Data Warehouse, Wiley, (ISBN 0-471-56960-7, lire en ligne)
- Ralph Kimball, The Data Warehouse Toolkit, Wiley, (ISBN 978-0-470-14977-5), p. 237
Voir aussi
[modifier | modifier le code]Articles connexes
[modifier | modifier le code]- Les grands éditeurs de bases de données pour entrepôt de données : IBM, Oracle, Teradata, Microsoft et Sybase IQ.
- Datamart
- Datamining
- Modèle de données dit « en étoile » ou « en flocon »
- Executive Information System
- Hadoop
- Informatique décisionnelle
- Modélisation dimensionnelle
- Online Analytical Processing
- Lac de données (Data lake)