Интерпретатор (рачунарство)
Овом чланку је потребна лектура текста. То подразумева исправку граматичких, правописних и интерпункцијских грешака или тона. |
| Извршење програма |
|---|
| Опште теме |
| Специфична дужина трајања |
|
Интерпретатор или интерпретер (енгл. interpreter), у рачунарству, је програм који извршава код написан у неком програмском језику.
У компјутерској науци, преводилац је компјутерски програм који директно извршава, односно обавља, упутства написана у програмском или скрипт језику, без претходног састављања у машину језика програма. Интерпретатор углавном користи једну од следећих стратегија за извршење програма:
- анализира изворни код и обавља своје понашање директно.
- преводи изворни код у неки ефикасни међујезик и одмах изврши то.
- изричито извршава и чува већ компајлирани код [тражи се извор] направљен од стране компајлера који је део преводиоца система.
Ране верзије Lisp програмског језика и Dartmouth BASIC ће бити примери прве врсте. Perl, Python, MATLAB и Ruby су примери друге, док UCSD Pascal је пример треће врсте. Извори програма су унапред састављени и складиштени као машински независни кодови, који се затим повезују у рун-тиме и изводи их интерпретатор или компајлер (за ЈИТ систем). Неки системи, као што су Smalltalk, савремене верзије BASIC, Java и други могу да комбинују два и три.
Док тумачење и компилација су два главна средства помоћу којих програмски језици се примењују, нису међусобно искључиви, као и већина интерпретационих система такође обављају преводилачки рад. Изрази "интерпретациони језик" или "састављен језик" значи да је примена тог језика од стране тумача или преводилаца, респективна. Језик на високом нивоу је идеално апстракција независтан од појединих имплементација.
Историја
[уреди | уреди извор]Први преводилац језика на високом нивоу био је Lisp . Lisp је први пут реализован 1958. године Steve Russell на IBM 704 компјутер . Расел је читао John McCarthy's папир, и схватио ( да John McCarthy's изненађује ) да би Lisp функција евал могла бити реализована у машински код . [ 2 ] Резултат је био радни Lisp преводилац који би се могао користити за покретање Lisp програма, или тачније, " проценити Lisp израз " .
Компајлер верзије преводилаца
[уреди | уреди извор]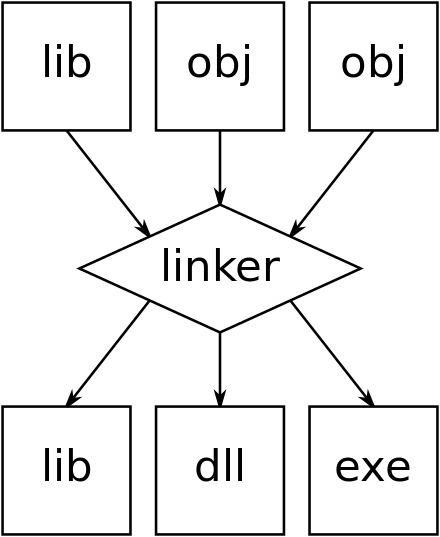
Програми писани на високом нивоу језика су или директно обављали неку врсту преводиоца или су претворени у машински код од стране компајлера (и асемблер и veznik) за процесор ко треба да изврши. Док компајлери (и монтери) углавном производе машински код директно извршен од рачунарског хардвера, они се често (опционо) могу произвести у средњем облику названом објектни код . Ту је у основи специфичан код исте машине, али појачан са симболима, са именима и ознакама које дају извршни блокови (или модули). Конструкциони програми ће обично користити градивне блокове (функције) да их чува у библиотеку таквих модула. Спојница се користи за комбиновање (ПРЕ-маде) библиотеке фајлова са циљем да се формира у једну извршну датотеку. Фајлови објекта који се користе за генерисање извршне датотеке се тако често произведу у различитим временима, а понекад чак и у различитим језицима (способност стварања истог објекта).
Једноставни преводилац написан у језику ниског нивоа (нпр асемблер) могу да имају сличне машинске кодове који спроводе функције језика на висок ниво, складишти и извршава када функција указује на то. Међутим, преводилац написан на високом нивоу језика обично користи другачији приступ, као што су стварање, а затим анализа, или генерисање и извршавање међу резултате упутства софтверски дефинисане, или обоје.
Дакле, оба компајлера као и преводиоци углавном окренути ка изворном коду (текстуални фајлови) на токене, како могу (или не могу) генеришу стабло извођења, и тако може генерисати хитне инструкције (за стек машину, четвороструки код, или на други начин). Основна разлика је у томе сто преводилачки систем, укључујући (изграђена или одвојено) линкер, генерише самосталну машину код програма, док преводилачки систем обавља радње описане програмом на високом нивоу.
Компилирање може на тај начин скоро све конверзије из изворног код семантике да пребаци на ниво машине једном за свагда (односно до програм мора да се промени), док преводилац мора да уради неке од овог посла конверзије. Међутим, на ефикасан начин преводиоца, велики део превода рада (укључујући анализу врсте, и слично) се урачуна и ради само први пут као што је програм, модул, функција, или чак изјаве, то је прилично слично како преводилац ради. Међутим, састављен програм и даље ради много брже, у већини случајева, делом зато што компајлери су дизајнирани за оптимизацију кода, и може им се дати довољно времена за то. Ово нарочито важи за једноставније језике на високом нивоу без (много) динамичке структуре података, провере или куцања.
У традиционалној компилацији, извршни излаз на везнике (.exe фајлове или .dpl датотеке или библиотеке) је обично премештен када ради под општим оперативним системом, слично као модули објектног кода али са том разликом што ово премештање врши динамичко време извршавања, односно када програм учита извршење. С друге стране, он је саставио и повезао програме за мале уграђене системе и обично се статички додељују, често тешко кодирани у НОР флеш меморији, јер често нема средњег складиштења и нема оперативног система у том смислу.
Историјски, већина тумачких система су имали едитор само-садржине. Ово је све чешће и за компилаторе (тада често назива. IDE), иако су неки програмери волели да користите едитор по свом избору и покрену компајлер, линкер и друге алате ручно. Историјски, компајлери јесу преводиоци, јер хардвер у то време није могао да подржи друге преводиоце и тумаче кода као и типично окружење временски ограничене предности тумачења. [тражи се извор]
Развојни циклус
[уреди | уреди извор]Током развоја софтверског циклуса, програмери дају честе промене на изворном коду. Када користите компајлер, сваки пут када се изврши измена у изворном коду, они морају да чекају преводиоца да преведе измењене изворне фајлове и да их повеже све по бинарном коду датотеке заједно пре него што програм може бити погубљен. Што је већи програм, дуже је чекање. Насупрот томе, програмер помоћу преводиоца чини много мање на чекању, као преводилац обично само треба да преведете код (или не преведе га уопште), што захтева много мање времена пре него што промене могу бити тестиране. Ефекти су видљиви након спасавања изворног кода и претоварања програма. Приредити код је генерално мање лако него отклањање грешака као уређивање, прикупљање и повезивање јер су секвенцијални процеси који треба да се спроводе у правом редоследу са одговарајућим сетом команди. Из тог разлога, многи компајлери имају извршну помоћ, познату као Марка датотеке и програма. Марку листе фајлова компајлер и линкер су командне линије изворног кода програма фајлова, али могу узети једноставне командне линије менија улаза (нпр "Маке 3") који бира трећу групу (комплет) инструкција затим издаје команде за компајлер, и везује наведене фајлове изворног кода.
Дистрибуција
[уреди | уреди извор]Компајлер претвара изворни код у бинарни упутством из конкретне архитектуре процесора, Ова конверзија се врши само једном, на окружење програмера, а након тога исти бинарни може се поделити на рачунар корисника, где се може извршити без даљег превода. Крст компајлер може да генерише бинарни код за разумљивост машине, чак и ако има другачији процесор од машине у којој је саставио код. Интерпретирани програм може да се дистрибуира као изворни код. Потребно је да се преведе у свакој завршној машини, која захтева више времена, али чини дистрибуцију програма независно од архитектуре машине. Међутим, преносивост тумачења изворног кода зависи од мета машина које заправо имају одговарајућу улогу преводиоца. Ако тумач треба да се испоручује заједно са извором, укупни процес инсталације је сложенији него достављање монолитно извршне јер је сам интерпретатор део онога што треба да се инсталира. Чињеница да тумачење кода може лако да се прочита и копира, људи могу бити од интереса за народна ауторска права. Међутим, различити системи шифровања и кодирања постоје. Испорука средњег кода, као што је бајткод, има сличан ефекат на замагљивања, али бајткод може да се декодира са декодером или растављањем.
Ефикасност
[уреди | уреди извор]Главни недостатак преводилаца је да тумачење програма обично ради спорије него да га састави. Разлика у брзини може бити мала или велика; често реда величине а понекад и више. То обично траје дуже да покренете програм преводиоца него да покренете компајлере али може узети мање времена да га преведе од укупног времена потребног за састављање и покретање. Ово је посебно важно код прототипова и тестирања кода када едит тумачења-дебуг циклус често може бити много краћи него едит састављања-рун-дебуг циклуса.
Тумачење кода је спорије него када се преводи код, јер преводилац мора да анализира сваки изјаву у програму сваки пут када се извршава, а затим изврши жељену акцију, док састављени код само обавља радње у фиксном контексту да одреди компилације. Ова Рун-тиме анализа је позната као "тумачења над главом". Приступ варијабли је такође спорији код преводиоца, јер мапирање идентификатора локација за складиштење мора да се уради више пута у рун-тиме него код компајлирања.
Постоје разни компромиси између брзине развоја када се користи преводилац и брзине извршавања када користите компајлер. Неки системи (као што су неки Lisp-ови) омогућавају тумачење и састављање кода за позивање једни других и да деле променљиве. Многи преводиоци не извршавају изворни код како треба, али га претварају у још компактну интерну форму
| Алатка C програмског језика |
|---|
// data types for abstract syntax tree
enum _kind { kVar,kConst,kSum,kDiff,kMult,kDiv,kPlus,kMinus,kNot };
struct _variable { int *memory; };
struct _constant { int value; };
struct _unaryOperation { struct _node *right; };
struct _binaryOperation { struct _node *left, *right; };
struct _node {
enum _kind kind;
union _expression {
struct _variable variable;
struct _constant constant;
struct _binaryOperation binary;
struct _unaryOperation unary;
} e;
};
// interpreter procedure
int executeIntExpression(const struct _node *n) {
int leftValue, rightValue;
switch (n->kind) {
case kVar: return *n->e.variable.memory;
case kConst: return n->e.constant.value;
case kSum: case kDiff: case kMult: case kDiv:
leftValue = executeIntExpression(n->e.binary.left);
rightValue = executeIntExpression(n->e.binary.right);
switch (n->kind) {
case kSum: return leftValue + rightValue;
case kDiff: return leftValue - rightValue;
case kMult: return leftValue * rightValue;
case kDiv: if (rightValue == 0)
exception("division by zero"); // doesn't return
return leftValue / rightValue;
}
case kPlus: case kMinus: case kNot:
rightValue = executeIntExpression(n->e.unary.right);
switch (n->kind) {
case kPlus: return + rightValue;
case kMinus: return - rightValue;
case kNot: return ! rightValue;
}
default: exception("internal error: illegal expression kind");
}
}
|
Тумач може добро користити исти лексички анализатор и анализатор као преводилац а затим интерпретирати добијену апстрактну синтаксу стабла. Пример дефиниције типа података за ово друго, и алатка тумача за синтаксе стабала добијених из C израза су приказани у кутији.
Регресија
[уреди | уреди извор]Тумачење не могу користити као једини начин извођења: иако преводилац се сам по себи тумачи и директно извршава програм негде где је потребно слагање медијума, јер код се тумачи, по дефиницији, исто као код машина које процесор може да изврши. [тражи се извор] [тражи се извор]
Варијације
[уреди | уреди извор]Бајткод преводиоци
[уреди | уреди извор]Постоји спектар могућности између тумачења и састављања, у зависности од количине анализе извршене пре него што се програм извршава. На пример, Emacs Lisp је састављен од бајткода, што је компримовано представљање Lisp извора, али није машински код (и стога није везан за било ког хардвера). Овај "састављен" код се затим тумачи преко бајткод преводиоца (сама написан у Ц). Преведени код у овом случају је машински код за виртуелну машину, која се не спроводи у хардверу. Исти приступ се користи са Форт кода који се користи у Open Firmware система: извор језика је састављен у "Ф" коду (бајткод), који се затим тумачи од стране виртуелне машине Контролна табела - код ње није потребно да прође кроз фазу састављања -где се диктира одговарајући алгоритам, ток контроле путем прилагођених тумача на сличан начин
Сажетак Синтаксе преводилаца
[уреди | уреди извор]У спектру између тумачења и састављања, други приступ је да се трансформише изворни код у оптималну апстрактну синтаксу стабла (аст), а затим изврши програм који прати ове структуре стабала, или га користити за генерисање нативе кода само-у-времену. [6 ] У овом приступу, свака реченица треба се анализирати само једном. Као предност над бајткодом, АСТ држи глобалну програмску структуру и односе између изјава (које је изгубио у представљању бајткода), када компримовани пружа више компактна представљања. [тражи се извор] На тај начин, користећи АСТ је предложен као бољи средњи формат компајлерима него као бајткод. Такође, омогућава систему да боље раду анализе током рунтиме-а.
Међутим, за преводиоце, један АСТ узрокује преко границе више него бајткод преводилац, јер чворови који се односе на обављање синтаксе немају користан рад, а мање секвенцијална репрезентација (која захтева већи број показивача).
Динамички превод
[уреди | уреди извор]Иначе, стварају разлику између преводилаца, бајткод-а преводиоца и компилације (ЈИТ), техника у којој је међупроизвод састављен на матерњем машинском коду у рунтиме-у. Ово даје ефикасност ради нативе кода, по цени од покретања времена и повећане употребе меморије када се први пут саставља бајкткод или АСТ. Адаптивна оптимизација је комплементарна техника у којој преводилац промовише програм рада и састављања. Обе технике се неколико деценија, појављују на језицима као што је Smalltalk у 1980-их. [тражи се извор] У тренутку компилације придобио је пажњу међу језичким реализаторима у последњих неколико година, са Јава, .NET Framework,, већина модерних JavaScript имплементација, и Matlab сада, укључујући JITs
Самостални интерпретатор
[уреди | уреди извор]Самостални преводилац је програмски језик написан у неком програмском језику који може да се протумачи; пример је основни преводилац написан у BASIC. Самостални преводиоци су везани за самоодржавајуће преводиоце. Ако нема, компајлер постоји за језик да се протумачи, да ствара себи преводиоца и да захтева примену језика у језику домаћина (који може бити још један програмски језик). Имајући првог преводиоца, као што је ова, систем је унапређен и нове верзије тумача могу се развити у самом језику.Donald Knuth је развио групу преводиоца за језик WEB који је писан на домаћем језику. Дефинисање компјутерског језика обично се обавља у односу на апстрактне машине (тзв оперативних семантика) или као математичка функција (денотациона семантика). Језик може такође бити дефинисан интерпретатором у коме је семантика матерњег језика дата. Дефиниција језика од стране сопственог преводиоца није утемељена (не може дефинисати језик). Она такође омогућава преводиоцу да тумачи њен изворни код, први корак ка рефлектујућем превођењу Важна димензија у имплементацији сопственог преводиоца је да ли се карактеристика интерпретираног језика реализује са истим особинама на матерњем језику преводиоца. Што се више карактеристике спроводи функције матерњег језика, мање контроле програмер преводиоца има; другачије понашање за бављење броја поплава не може се реализовати ако аритметичке операције делегирају одговарајуће операције у матерњем језику. Неки језици имају свог одговарајућег преводиоца, као што је Lisp или Prolog. Многа истраживања о локалним преводиоцима су спроведена на Scheme програмском језику, дијалекту Lisp-а. У принципу, било која Тјурингова потпуност омогућава писање сопственог преводиоца. Lisp је такав језик, јер Lisp програми су листе симбола и других листа. XSLT је такав језик, јер XSLT програми су писани у XМL. Под-домен мета програмирања је писање домена специфичних језика (DSLs). Clive Gifford увео је квалитет мера само-преводиоца, лимит односа времена проведеног компјутерским радом. Ова вредност не зависи од програма који беже. Књига Структуре и тумачења компјутерских програма представља примере мета-кружних тумачења за шеме и његове дијалекте. Други примери језика самосталних преводиоца су Forth и Pascal.
Апликације
[уреди | уреди извор]- Преводиоци се често користе за извршење команде језика, и скриптног језика, јер сваки оператер извршава у командном језику обично са позивањем на сложене рутине као што је уредник или компајлер.
- Само-модификујући код може лако бити реализован . Ово се односи на порекло тумачења у Lisp и истраживања вештачке интелигенције.
- Виртуелизација. Машински код намењен једној хардверској архитектури може се покренути на другом користећи виртуелну машину, што је у суштини био преводилац.
- Sandboxing: Тумач или виртуелна машина није приморан да заправо извршава сва упутства изворни код је обрађује. Конкретно, то може да одбије да изврши код који прекрши било безбедносне ограничења се раде под.
Преводилац бушене картице
[уреди | уреди извор]Термин "преводилац" често позива команду јединице опреме да читају бушене картице и штампа ликове у људском облику читљиве на картици. IBМ-550 Бројни преводилац и IBМ-557 Абецедни преводиоци су типични примери из 1930. и 1954. године.
Види још
[уреди | уреди извор]Напомене и референце
[уреди | уреди извор]- ^ У том смислу, процесор је преводилац, инструкција машине.
- ^ Према ономе што је пријављено од стране Paul Graham y Hackers & Painters, стр. 185 McCarthy је рекао: "Steve Russell је рекао, види, зашто не бих програм ову ... и ја сам му рекао, хо, хо, ви сте побркали теорију са праксом, ово је намењено за читање, не за рачунарство. Али он је отишао и урадио то. Он саставио у свом раду у IBM 704 машински код, фиксирање грешке, а онда је рекламирао ово као Lisp преводилац. Дакле, у том тренутку Lisp је имао у суштини облик који има данас ... "
- ^ "Why was the first compiler written before the first interpreter?". Ars Technica. Приступљено 9 November 2014.
- ^ Theodore H. Romer, Dennis Lee, Geoffrey M. Voelker, Alec Wolman, Wayne A. Wong, Jean-Loup Baer, Brian N. Bershad, and Henry M. Levy, [тражи се извор] The Structure and Performance of Interpreters
- ^ Terence Parr, Johannes Luber, [тражи се извор] The Difference Between Compilers and Interpreters
- ^ AST intermediate representations, Lambda the Ultimate forum
- ^ A Tree-Based Alternative to Java Byte-Codes, Thomas Kistler, Michael Franz
- ^ Surfin' Safari - Blog Archive » Announcing SquirrelFish. Webkit.org (2008-06-02). Приступљено 2013-08-10.
- ^ L. Deutsch, A. Schiffman, Efficient implementation of the Smalltalk-80 system, Proceedings of 11th POPL symposium, 1984.
Спољашње везе
[уреди | уреди извор]- IBM Преводиоци страница на Колумбијском универзитету
- Теоријске основе за практичну функционалност програмирања(Поглавље 7), посебна Докторска дисертација решавања проблема формализовања шта је преводилац
- Кратка анимација објашњава кључну концептуалну разлику између тумача и преводиоца